#90 Figma Deep Search 扩展试验
Chrome 扩展试验,用于优化 Figma 搜索结果展示

Figma Deep Search 是一个基于 Chromium 的浏览器扩展。它会在你搜索 Figma 文件时,展示搜索的文本来自文件哪里。
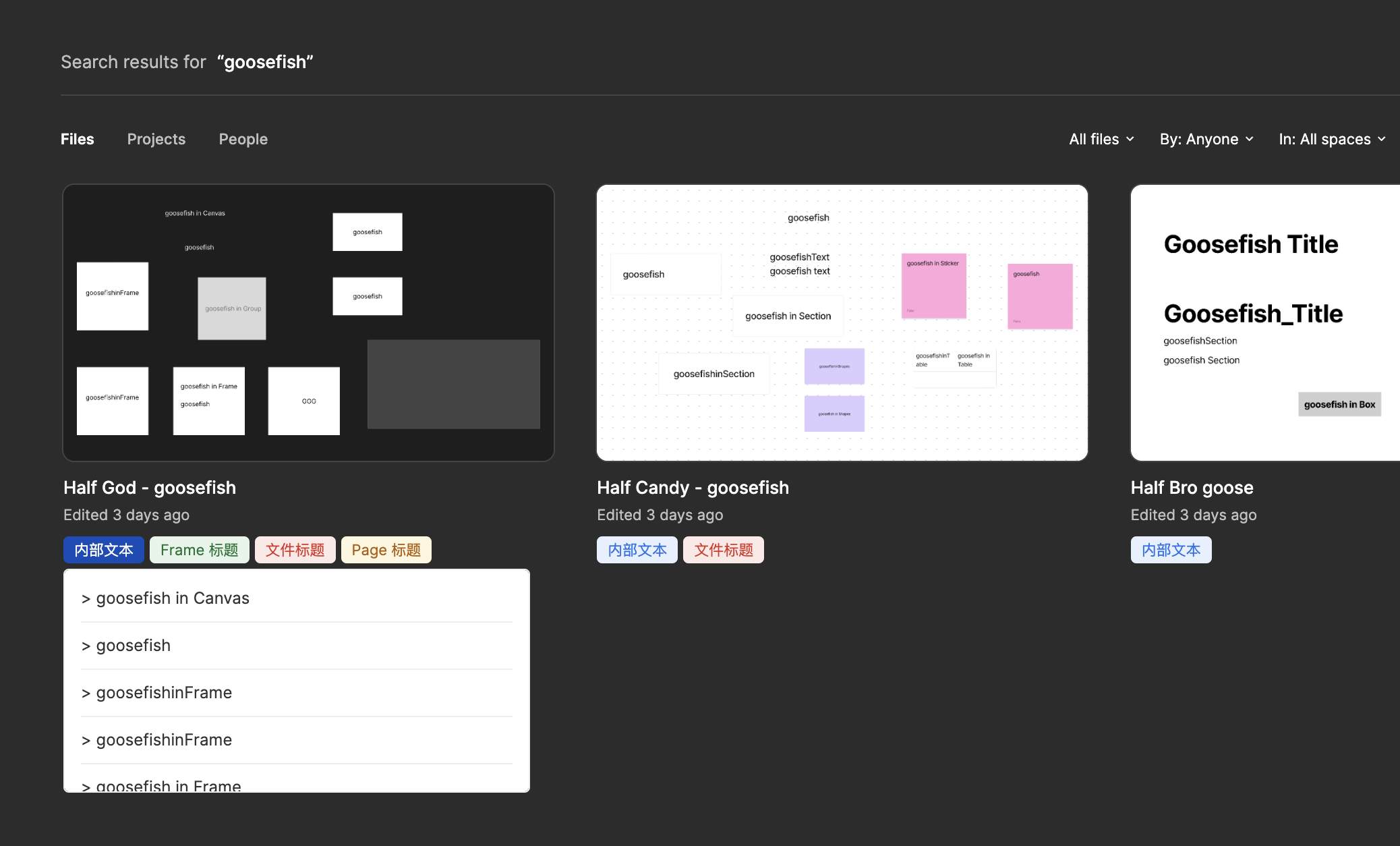
如果你填写了 Figma personal access token,那么点击标签可以看到所有相关节点(上图白色弹窗),再点击节点即可在新标签页中打开已定位的设计文件。
这个扩展只是一个想法验证,所以没有打磨细节和体验,当然也没有交 5 美元的「朋友费」。已开源:
使用
建议配合浏览器快捷搜索使用:
https://www.figma.com/files/team/{你的任意teamid}/search?q=%s
或者 Raycast Quicklinks:
https://www.figma.com/files/team/{你的任意teamid}/search?q={Query}
展示来源标签
虽然想说这个浏览器扩展名字有蹭 deep %any% 的嫌疑,但是 Figma 2020 年文章确实称之为 Deep Search ↓

它的原理大致是,从你密集操作的设计文件中,每小时单独处理文件中的各种文本,将其作为单独的 text_instances 存储起来,这样在你搜索某些关键词时,可以直接搜索到文件内部图层(节点)的文本。也是因为如此,刚添加的文本是搜索不到的,需要等待一段时间。
不过 Figma 并没有依此完善搜索结果,并且限制了搜索 API 范围(无法搜索 drafts 中的文件)。
可实际在 Figma 中搜索是能搜到 drafts 文件的,打开浏览器 devtools 找了一下,都在 /api/search/full_results 里面,每个返回的文件大致结构为:
{
"model": {
...
"key": "文件 key",
"name": "文件名",
"editor_type": "design",
"url": "文件 url",
"thumbnail_url": "封面缩略图 url",
...
"owner": {
"id": "Figma UID",
"img_url": "头像地址",
"handle": "Fenx",
"email": "注册邮箱"
}
},
"score": 1774.2072,
"matched_queries": [
"deep-search-text",
"frame-name",
"fuzzy-name",
"name-word-delimiter-v2",
"name-word-delimiter-v2-with-or",
"page-name"
]
}
该 API 请求需要 cookie,所以用浏览器扩展实现比较方便。
而 matched_queries 它的对应关系可能是这样的:
- "deep-search-text":内部某处图层的文本
- "frame-name":Frame 标题
- "page-name":Page 标题
- "fuzzy-name":文件名标题
- 剩下两项可能是涉及分词的精准匹配度
最终会得到一个 “score” 来做为搜索匹配度,score 越高相关性越高,也就是默认的 relevance 排列顺序。
扩展的第一步工作就是把这 4 个作为标签映射出来。比如显示的是「内部文本」标签,那么便可以点进去直接按 ⌘+F 搜索全部 page。
搜索节点
在上一步返回的结果中我们可以顺手拿到设计文件的 key 值,它是每个 figma 文件的唯一 id。平时在分享网址中也可以看到:
https://www.figma.com/{文件类型}/{Key}/{文件名}?node-id={nodeID}
Figma 的 REST API 中,GET /v1/files/{key} 可以用于获得文件的所有节点信息。此操作需要个人 token 鉴权。
curl -H 'X-FIGMA-TOKEN: <personal access token>' 'https://api.figma.com/v1/files/:file_key'
返回的结果有很多元信息,但这里只搜索 "name" 和 "characters" 字段。
Text(分为图层名和文本内容两种)
"id": "1:2",
"name": "goosefish in Canvas",
"type": "TEXT"
"characters": "goosefish in Canvas"
---
Page
"id": "0:1",
"name": "Page 1",
"type": "CANVAS"
---
Frame
"id": "4:7",
"name": "goosefish",
"type": "FRAME",
---
Group
"id": "1:7",
"name": "Group 1",
"type": "GROUP",
匹配上的再查找同一层级的 "id" 和 "type",将 "type" 与上面标签匹配,"id" 用于构造访问文件的 url(文件名不可用带上)。
Slides 虽然也是差不多的结构,但是本 API 不支持,无法查询。
优化方向
虽说实现了节点级别的搜索,但实际上没我想象的直观。可能每个节点需要更多的上下文信息,以更方便确认哪个节点是我们想要寻找的结果。所以文件内的全局搜索还是很有优势的,配合扩展一起使用起码不会像以前那样看着一堆莫名其妙的文件没有头绪。
Figma 个人 token 会使用 chrome.storage API 存储,未加密,这样很不好……建议用完随时清理 token 或者不填写。
本扩展依然是由 Cursor 完成,花费了 20 多个 request。感觉有不少冗余的代码,又让开发 dalao 们见笑了。
另外如果你的广告扩展屏蔽了某些 Figma 域名(例如 www.figma.com/api/figment-proxy/monitor)那么标签的展示可能会有 bug。
如果你觉得文章对你有些帮助,可以请我的猫吃罐头 ↓
