#85 偷窥 Ferret-UI
不做论文分析,单纯以看一篇文章的角度,摘记吐槽二三

为什么说「偷窥」呢?本人既不懂模型技术,也未紧跟 LLM 潮流。不做论文分析,单纯以看一篇文章的角度,摘记吐槽二三。可能有错误,不吝赐教。
自我介绍
Ferret-UI 是专为理解用户界面用的多模态 LLM,能够识别一些界面元素,感知交互以及一定的推理能力。
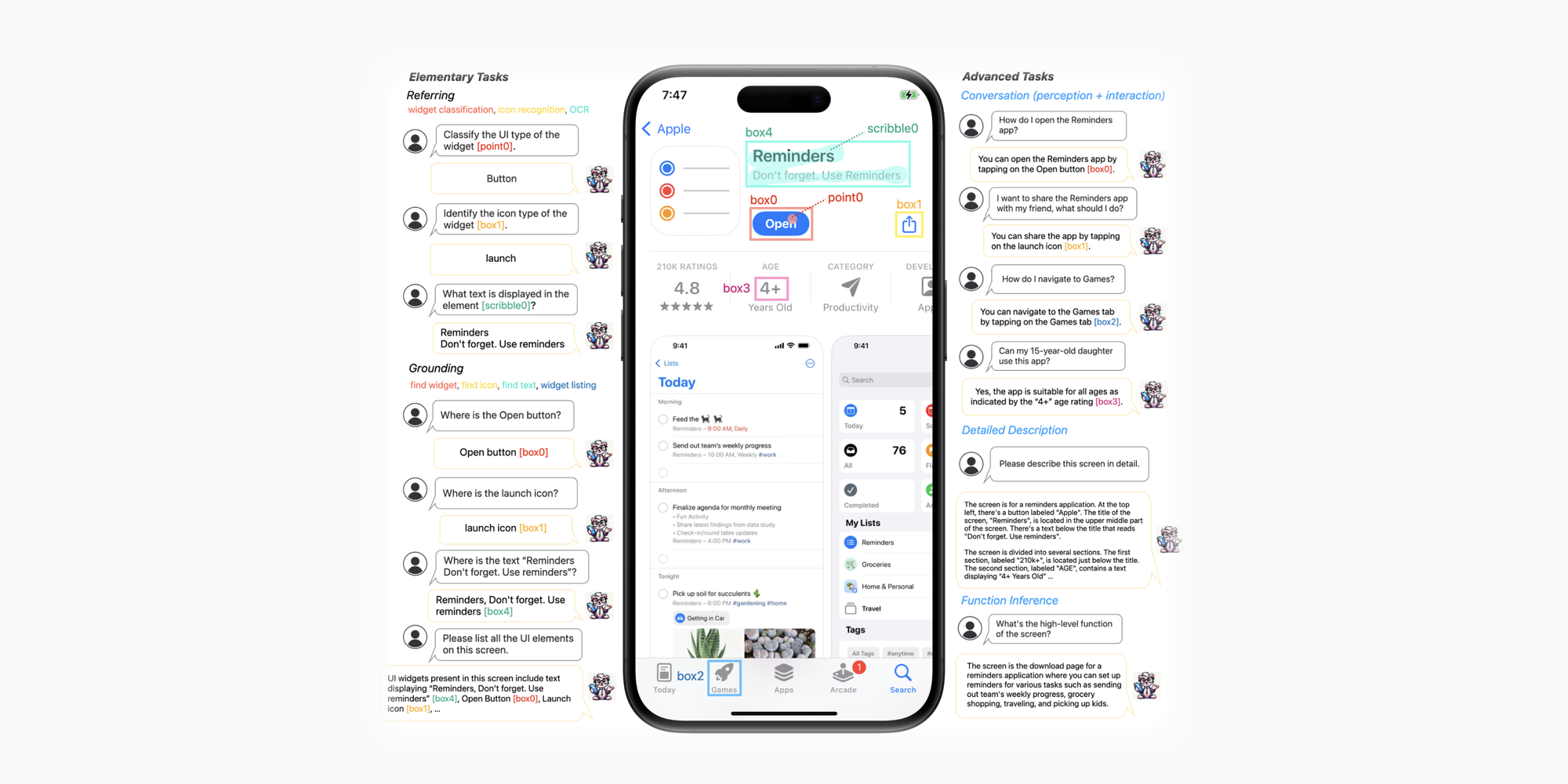
上图能很清晰地表示 Ferret-UI 的能力,包括:
- 通过点、框、划的方式识别界面元素(左上);
- 通过提问方式定位元素(左下);
- 高级推理任务,像回答一些基础交互操作,描述界面及其功能(右侧);
但就这些功能来看,可在测试和无障碍中大放光彩。未来加强对多界面的识别度提升,用自然语言生成快捷指令将大大提高系统使用效率。
Anyres
Apple 团队不想让 Ferret-UI 懂代码,只想让它做一名单纯的设计师——只从视觉去理解 UI。之前发布的 Ferret 和其他 SoTA 模型一般都只擅长识别自然图片,对移动端 UI 这种细长比例的图经常眼前一黑。而且 UI 图中经常包含 caption 和图标等又小又抽象的低分辨率区块,在识别和定位上都差强人意。
有问题就要解决,针对分辨率这里,团队提出了基于Ferret 的 Ferret-UI-anyres 架构:
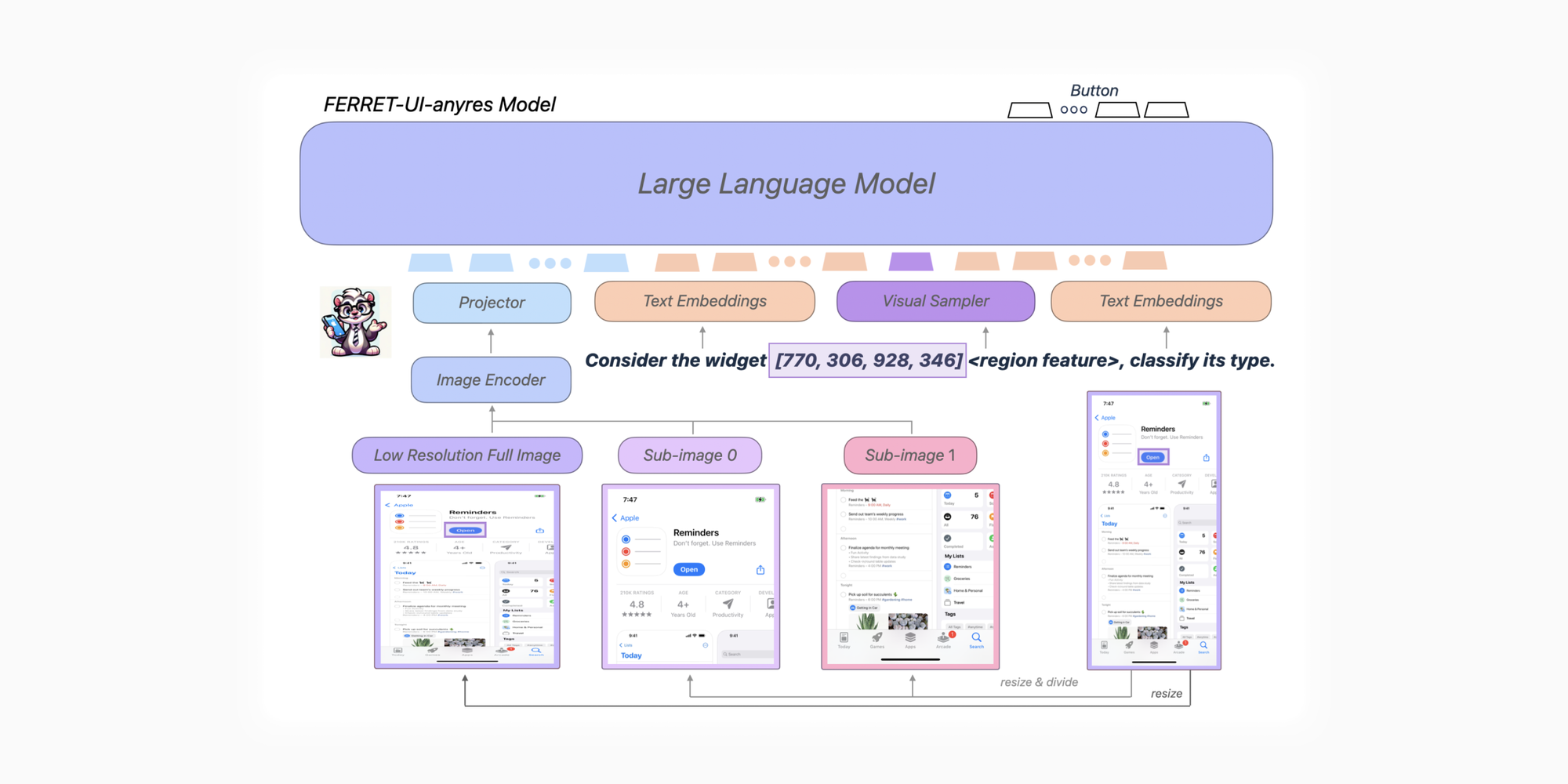
与 ScreenAI 采用的基于输入图像的形状和预定义的网格分块技术 Pix2struct 不同,anyres 这里先直接挤压图片(到正方形)通过预训练的图片编码器和投影层得到一个图像特征,然后将图片分成 1 x 2 的网格裁剪成两个 sub-image 获得额外特征(上图左侧流程)。当前的全面屏界面大多是接近 1:2 的比例,贴合实际。
Visual Sampler 是一种独特的混合技术,用来管理不同区域的连续特征,方便 LLM 处理数据。一切为了 LLM!
Text Embeddings 大概就是猛灌专家知识,从零开始学 UI!以及定义一些任务,任务的数据从之前的 Spotlight 借鉴(也是 Google 的)并重新用 GPT-3.5 Turbo 格式化。原论文第 4 部分详细描述了这些任务。
制定任务

如上图,检测器先列出了屏幕中的所含元素,从 0-17 编好序号,这些组件的类型、文本以及坐标都被记录用于后续的基础任务。
坐标数据指的是区域内左上角和右下角的坐标值,如下图格式便是 [700, 230, 1700, 730],比较符合设计直觉。

然后利用 GPT 的 QA 列举 widget 塞进一个采样里。这里的 widget 并非 HIG 中的小组件, 而是各种组件(components),很奇怪这里的术语歧义。
Listing 这里让我想起了正在用的 Tana 笔记,对于复杂格式的数据,Tana 也鼓励直接使用 AI 来按照一定格式输出整理。
根据右上角的 overview ,可以看到模型把每一类型数据(文本、图标等)都塞进了不同采样,为后续 QA 做准备:
- 所有检测数据都用于用于生成一个 widget listing 采样;
- 其中所有文本数据都用于生成一个 OCR 采样和一个 find text 采用;
- 其中所有图标数据都用于生成一个 icon recognize 采样和 find icon 采样;
- 其中所有非文本和图标数据都用于生成一个 widget classification 采样和 find widget 采样;
这里面的采样分别对应上述的识别和定位基础任务,每个采样对应的任务同样使用了 GPT-3.5 Turbo 扩写。数据类型划分的很简单,毕竟我们做 UI 的成天就那点事。
推理时间

虽然识别和定位任务已经优于 GPT-4V,但没有推理能力的话,对界面的理解还是不够深,一个文本既可以是按钮也可以是图标也可以是组件。高级任务这里是站在 LLaVA 的肩膀上,额外使用 GPT-4 新建了 4 个任务,并专注搜集训练 iPhone 界面数据。这 4 个任务分类为:
- 屏幕描述(detailed description):描述这个界面包含什么;
- 对话感知(conversation perception):对人类意图的理解,比如上图右下第一段 QA;
- 对话交互(conversation interaction):对交互流程的理解,比如上图右下第二段 QA;
- 功能推导(function inference):描述这个界面能实现哪些功能;
还是看图容易,图示上首先将检测到的元素坐标格式化为百分比定位,然后搭配一个公共 prompts(You are an AI visual assistance that can analyze mobile screens)、多个各种类型任务专用 prompts 以及专为对话准备的示意文本,统统交给 GPT-4,所以实际 QA 环节还是 GPT-4 在发挥哈,输出的源数据交回给 Ferret 处理。结果如上图右下角展示。在论文最后的附录中还能看到更多案例。
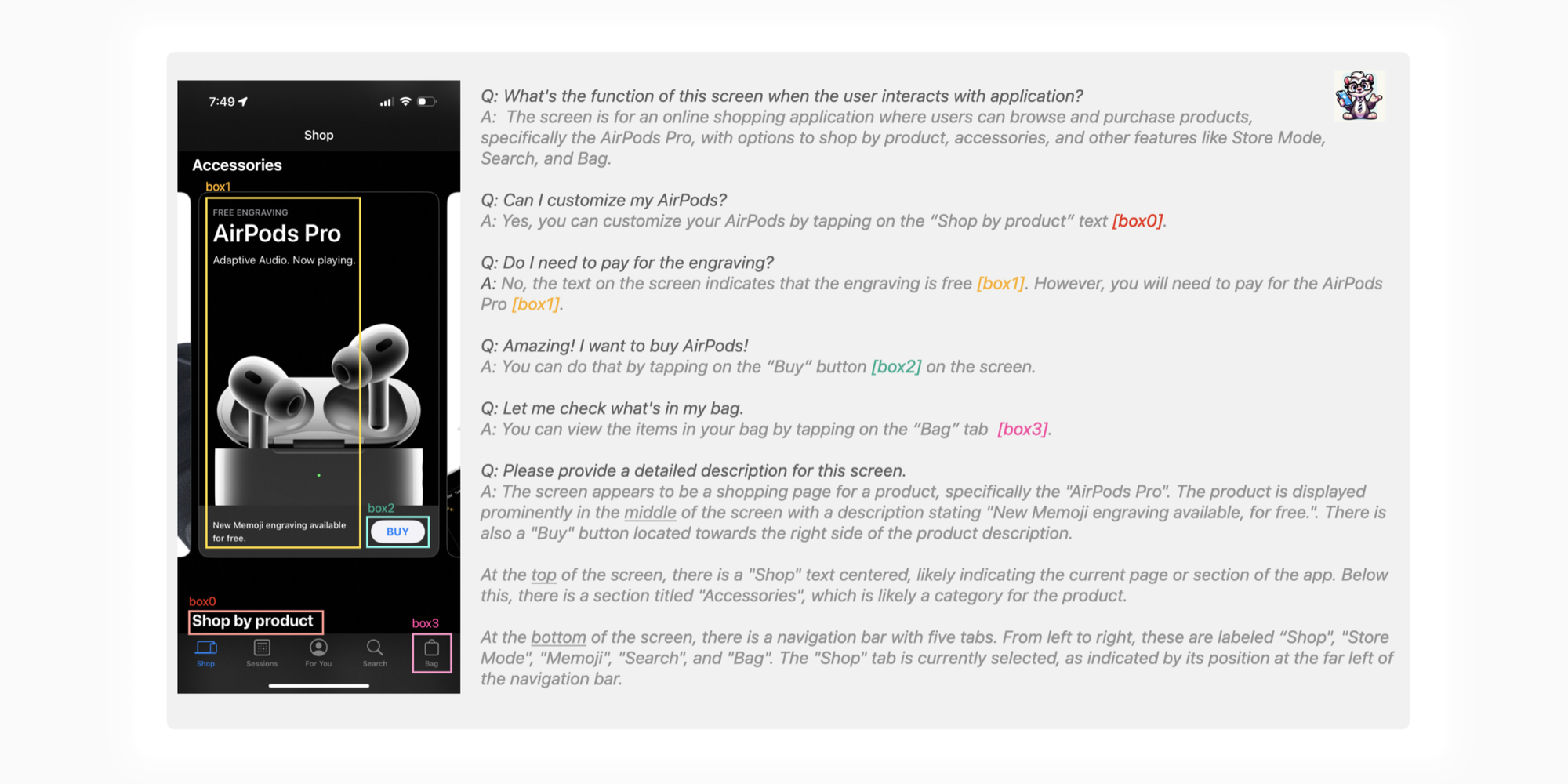
可以看到一些小字也识别的很精准。而且理解界面的过程完全是用户角度的,比如它会从商品图、Accessories 文案和购物袋图标识别推理出这是一个购物应用界面。🤔试想一下我们可以建立多个不同用户类型的心智模型,这些模型代表不同的画像,对界面的「观感」和理解也不同,这样设计早期阶段就能获得真实而又多面的反馈角度,商业化的名字我都想好了,就叫 Jury AI 吧。
数据集
毕竟是要公开的论文,Android 界面也要研究的。团队使用了 Rico 数据子集。Rico 是一个公共的用户界面数据集,囊括了大量 Android 截图和元数据,甚至还有交互路径和动画的数据,十分详细,就是老界面挺多的……里面有一项数据集叫 UI LAYOUT VECTORS,界面布局向量?它是这样的:
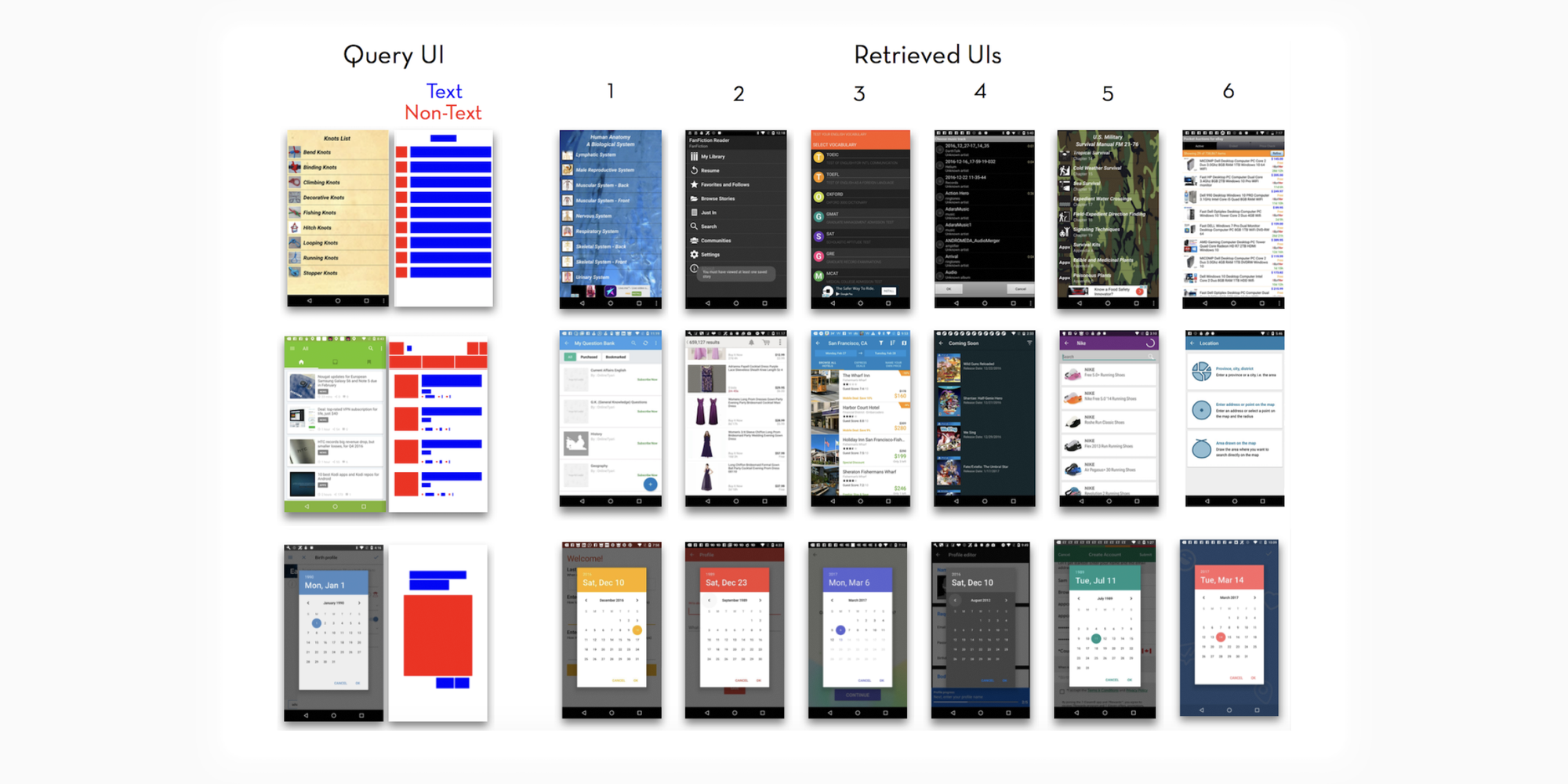
看到这图顿时一幕幕场景涌上心头——需求方发过来一堆风格和布局参考图,我一看这不都是同一种设计吗?对方还非常不解,这又是黑的白的又是彩色的,哪里一样呢?现在可以继续回答对面说,「你找的图布局向量都是相同的」,然后挥一挥衣袖扬长而去,瞥着对面什么时候上来追问「啥是布局向量啊」。
iOS 的数据集使用的是 AMP 一个随机子集。AMP 是苹果团队之前 Screen Recognition: Creating Accessibility Metadata for Mobile Applications from Pixels 项目产物。这个项目的目的是如何从 UI 中自动生成辅助功能元数据,来提高无障碍可访问性,毕竟目前的 VoiceOver 还只是无情的读屏机器。所以我一直有强调:
无障碍也可以提高无障碍人士的体验
Screen Recognition 项目结果是成功的,9 名视障用户甚至可以使用之前用不了的 App(很多 App 没有为无障碍标签做优化,比如大部分手机游戏)。一位参与者对发现「滚动条」很吃惊,因为这是他们第一次在 UI 中感受到这个组件存在。但当时 Screen Recognition 无法执行推理任务,不能识别一些图标的含义,以及执行一些手势交互。我不确定当年 iOS 14 VoiceOver 升级了一系列「识别」功能是否与这个有关。时光境迁,接力棒传到了 Ferret-UI 这边。
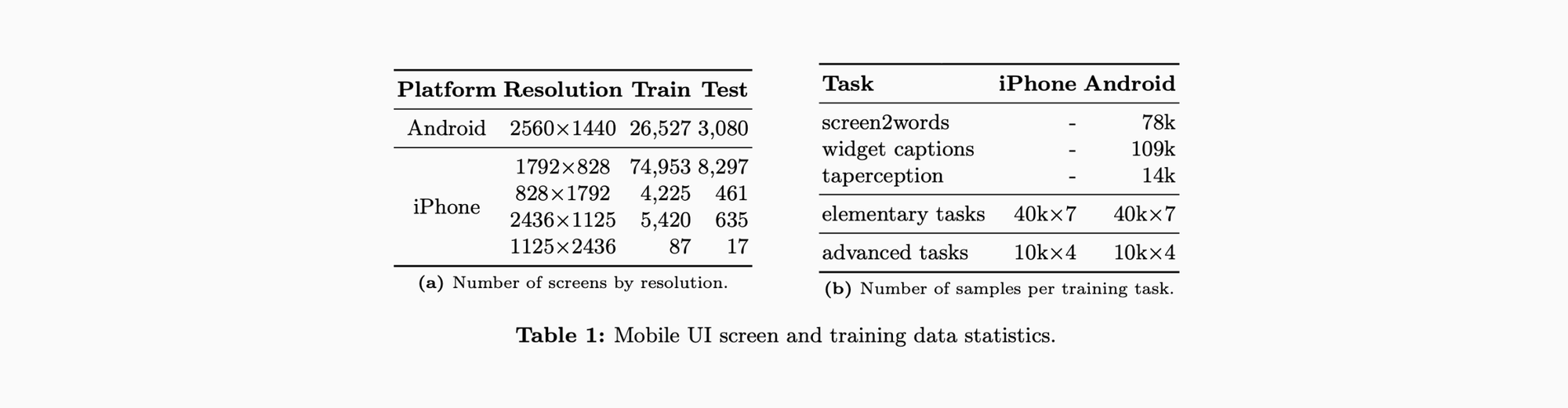
比起还在流行汉堡包菜单的 Android 界面数据集 [1],iOS 这边现代了一些,375 宽度和 414 宽度都有包含,并且包含了横屏界面截图。右侧任务数则是刚才提到的基础、高级两种任务,与之前的 Spotlight 流程任务相对比(后面会有说明)。
[1]: 实际上都是 1080*1920 分辨率截图,只不是指定了 bounding box 是 1440*2560。
结论
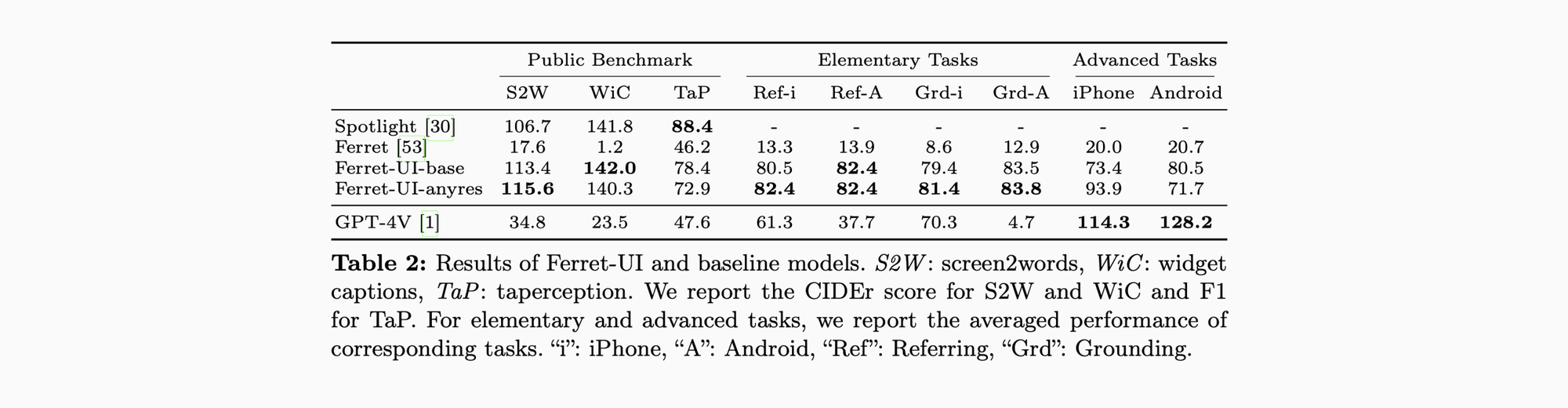
这里面 Public Benchmark 作为和 Spotlight 对比,团队也让 GPT-3.5 Turbo 对应生成了一系列 prompts 交给 Ferret-UI。基础 prompt 如下:
- Screen2words(S2W):提供屏幕截图描述总结;
- Widget Captions(WiC):对于一个可交互的元素,提供一段它的功能说明;
- Taperception(TaP):预测某个 UI 元素是否可点击;
结果显示 Ferret-UI 在这三项任务重取得了相当很有潜力的成绩,GPT-4V 则对此一脸懵,但在高级任务中,GPT-4V 背靠 GPT-4 这座大山依然占有不小的优势。而 Ferret-UI 对比 Fuyu 和 CogAgent 两位前辈已有不少进步。
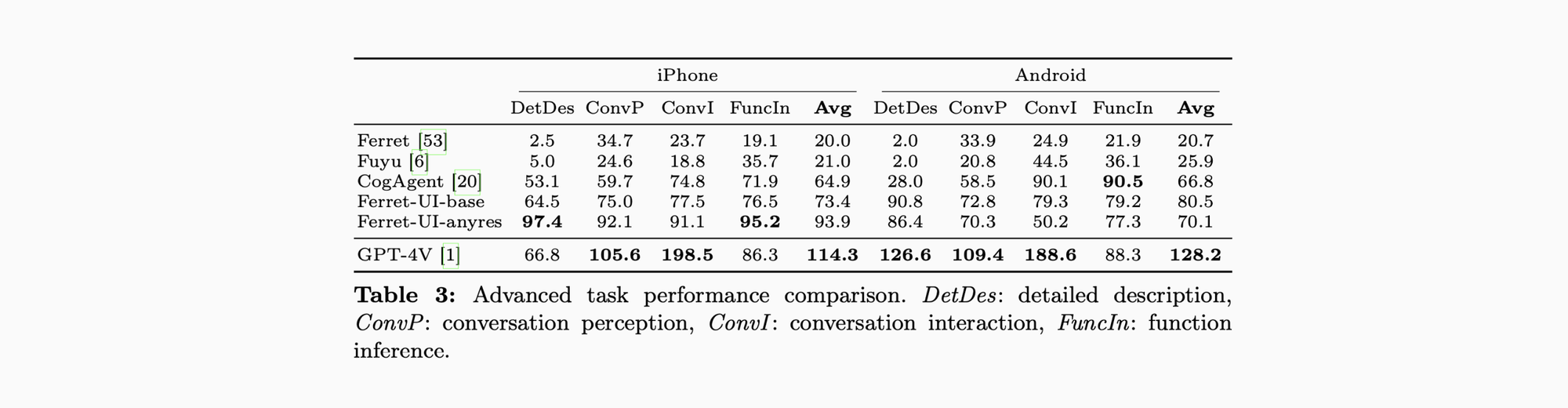
在消融实验中,对小号、手写和被挡住的文字识别依然较为准确。高级任务中对比 Spotlight 甚至略逊一筹,团队推测是训练数据不足,以及需要更复杂的 UI 术语理解。基础任务中的识别和定位也并非完美,一些复杂的组件结构和多次出现的文本都会扰乱模型的判断。”UI detection model is a bottleneck.”,检测器也是一大改进点。详细结果总结还是请看原论文。总之,Ferret-UI 还是相当有潜力的。
如果你觉得文章对你有些帮助,可以请我的猫吃罐头 ↓
