#94 如何设计测试 LLM 生成 SVG 能力的平台
全网最尊重宝可梦的 Benchmark

在等待 iOS App 审核的十天里,我从零搭建了一个测试 LLM 生成 SVG 的平台 Pokémon SVG Bench,通过 API 让各大 LLM 用最简单的 prompt 生成宝可梦 SVG,然后人工评估这些 SVG 的各项分数,并汇总为一个排行榜。可以在下方访问:

我一直在纠结要不要发布这篇文章,因为总觉得「把大家叫出来就这点事啊.jpg」。但我发现自从去年九月份就没有写过成形的文章,伴着愧疚于是有了下面的内容。
内容较长可能会被邮件截断,点击上方在浏览器中打开可以获得更好的阅读体验。
幕后
- 整体使用了 SvelteKit;
- Cloudflare Workers/Pages 负责部署运行;
- Cloudflare D1 负责结构化数据;
- Cloudflare R2 负责 SVG 原始文件、渲染快照等对象存储;
- Cloudflare Queues 负责 LLM 生成等后台任务;
- Cloudflare KV 可用于缓存公开榜单、短期会话或配置类数据;
- 后台使用 GPT-5.5 来初次搭建,大体结构没差但是有巨多的体验和性能优化问题;
- 后续迭代主要使用 Composer 2(当时还没 Composer 2.5),如果你关注我的 X 或许能看到我从 Composer 1.5 就开始夸了(Kimi 牛逼);
- 字体选用了 PP Pangram Sans Rounded 这种圆体;
- 颜色是从宝可梦官方 logo 取的黄蓝双色;
后台的流程主要是:测试数据 → 测试集 → 测试批次 → 配置供应商 → 配置模型 → 生成队列任务 → 数据初次打分评估 → 审核校对分数 → 配置剪影小游戏题库 → 发布模型 → 发布更新日志 → 展示
我只是一名设计师,不想在开发者面前班门弄斧,所以下方只会一一说明每个步骤的产品形态。
测试数据
搭建这种平台对 LLM 来说小菜一碟,我更期待的是从中学到了什么。
一开始,我先思考的是测试数据,也就是选择哪些宝可梦作为生成对象。这些宝可梦需要外形、颜色和知名度有一定的差异化,以及对应的验收标准,包括:
- 结构是否完整;
- 外形是否还原;
- 颜色是否准确;
- SVG 的构造是否高效;
正好宝可梦也有幼年期、成长期、成熟期、完全体、究极体(误)不同的进化阶段,打算分为多个层级来评估分数。52poke 的 wiki 中有按体形分类的页面,帮了很大忙。
- 阶段 1 (S1):主要是一些体型简单的宝可梦,来测试几何形状和颜色的还原度。比如胖丁(原型、粉色)、海星星(五角星、黄红色)等;
- 阶段 2 (S2):主要是一些有明确特征的宝可梦,来测试特征和空间比例的还原度。比如甲贺忍蛙的舌头围巾、吉利蛋的蛋、长尾火狐尾巴上的树枝等;
- 阶段 3 (S3):主要是一些大型复杂宝可梦,来测试结构和细节还原度。比如烈咬陆鲨(特殊的单趾手部、头部五角星)、哲尔尼亚斯(头上彩色的角)等;
由于我比较穷,出于生成/重试 API 成本、人工评估成本考虑,定为了每组 5 个宝可梦,共 5 x 3 = 15 个宝可梦为一个测试集。
- S1:胖丁、地鼠、海星星、美录坦、哈克龙;
- S2:六尾、蚊香君、长尾火狐、甲贺忍蛙、吉利蛋;
- S3:烈咬陆鲨、四颚针龙、阿尔宙斯、哲尔尼亚斯、巨金怪;
你可以在这个页面查看详细的宝可梦描述。至于为什么是「胖丁」而不是更圆润的「霹雳电球」,那就是私心❤了。

测试集和批次
在 Pokémon SVG Bench 后台可支持将不同测试数据整理成多个测试集。每个测试集需要标记状态、别名、描述等信息来生成评测批次。好处比如:
- 区分数据集建立状态,建立完毕、草稿、归档等;
- 区分测试和正式跑数据;
- 测试新一套宝可梦生成测试;
- 生成一些 bound 内容,比如我想额外生成一些宝可梦的奇葩外观(还没精力去做);
模型供应商
在生成数据之前需要配置 LLM 的 API。评测准则之一要尽可能使用原生的 API,所以也尽可能原生地去对接官方供应商。本身逻辑不复杂,少引入依赖也更安全一些。
但是像 Claude 和 OpenAI 的模型有官方限制,还是不得不用第三方,最后选择的是 Cloudflare 的 AI Gateway,里面的相关模型属于 proxy api,而且不会像 OpenRouter 有信用卡账单地址限制。
由于生成 SVG 用不上 agent loop(或者要尽量避免 tool-use),所以接入一个 OpenAI Chat Completions API 即可兼容大多数模型调用。额外的还需要再加上:
- Gemini 的 API 格式(虽然也有 Completions API 兼容);
- Quiver 的 API 格式;
- Workers AI,直接绑定模型 id 即可调用;
此外供应商这边还会输入:
- Base Url:完整的接入端点,不补全;
- Header json 字段:反正是自己用,直接填原生的请求头更方便;
- 并发数:针对一些供应商的低并发数,需要特别设置;
模型侧配置:
- 选择供应商;
- 模型对外显示名称;
- 模型调用时的 model id;
- 请求 body 的 json 字段:这里不会带有 message 字段,会在生成任务时根据不同的供应商自动拼合。因为 Cloudflare 的队列一段时间不接收数据会报错,所以这里一般会把流式传输打开;
- 约束 prompt:针对一些模型返回的 HTML 等非预期格式,需要额外简单约束一下只返回 SVG;
- 备注:模型的一些配置信息,以保持透明。比如针对
Claude Opus 4.8会声明Cloudflare Proxy API. Thinking: adaptive. Effort: high; - 测试:检测配置是否正确;
Prompt 统一配置为:
Generate the SVG code for the Pokémon {{pokemon_name}}
约束 Prompt:
Output only the SVG tag code. No additional text and tool call.
生成
现在有了评测批次和模型,终于可以合体——开始生成宝可梦 SVG 数据了。生成任务在填写信息后会进入 Cloudflare Queues 队列;
- 跑测试数据:可以额外输入测试数目,一般新模型会跑个 3-4 次测试来看是否能跑通,以及观察返回的格式是否需要约束;
- 跑正式数据:可以输入每个宝可梦的测试数目,出于成本和边际效应考虑,目前是 2 次。另外这里可再次输入 API 请求的并行上限,并以此为准;
队列的状态按顺序可分为:
- Pending:待进入队列,只要 Queues 没出问题一般会快速进入下一状态;
- Queued:排队中的任务;
- Processing:正在执行的任务队列,可手动重试和标记失败:
- Succeeded:成功返回数据的队列,数据会进入评分工作台;
- Failed:失败的任务,可手动重试;
由于可能会同时跑不同的模型队列,所以队列在结构上合并了同一批次,可以展开/收起某个批次队列。
失败的任务,会对应在评分工作台有提示,该批次缺少生成数据。像 GLM-5.1 我就遇到了重试多次超时无法正常返回数据的情况。无奈只能在别的地方手动 curl 出 SVG 再手动补充到测试批次的结果中。
手动上传我分为了两种:
- 单个 SVG 上传:需要选择评测批次、宝可梦、模型名称来限制上传到哪个数据结果。
- 这里需要注意的是,由于当前一个模型只会有一个激活的批次结果,所以这么选择姑且是 1 对 1 的。
- 批量上传:像 Cursor 的 Composer 模型,由于没有官方的外接 API。所以只能在产品中用 subagents 的形式来生成。生成后的 SVG 文件会根据文件名来识别是否满足一组完整的批次结果。最后选择对应的模型名字即可上传完毕。
- 我在供应商那边新建了个 Custom,用于承载这种没有公开 API 的模型。
打分
生成的 SVG 按业务需要也分为多种状态:
- 待评分
- 已评分
- 待校对:校对是为了防止类似质量的的 SVG 出现过大的分差,或者质量差别较大的 SVG 分差反而不大。
- 隐藏:测试数据不计入评分
由于宝可梦分为了三阶段,所以这三阶段的评分维度和权重也是不同的:
- S1:几何精准度 40%,色彩还原 20%,整体观感 40%;
- S2:特征识别 40%,空间比例 20%,整体观感 40%;
- S3:结构解构 40%,细节打磨 20%,整体观感 40%
每项分数均为 0-10 分。单个 SVG 分数即为:
S_i = 0.4 · d_1 + 0.2 · d_2 + 0.4 · d_3
计算出单个生成数据的分数后,同组内计算算术平均数,得出组平均数。由于每组本身难度也不同,计算总分时会再次按照 W_1 : W_2 : W_3 = 1.0 : 1.8 : 3.2 来加权。设每组数据个数为 N(目前为 5 x 2 = 10),组内平均分数值范围仍为 0–10,则加权总分的理论上限为 N × 10 × (W_1 + W_2 + W_3) = 600,最终分数归一化为百分制:
S_total = (S_1 · N · W_1 + S_2 · N · W_2 + S_3 · N · W_3) · 100 / 600
在前台会这样展示。
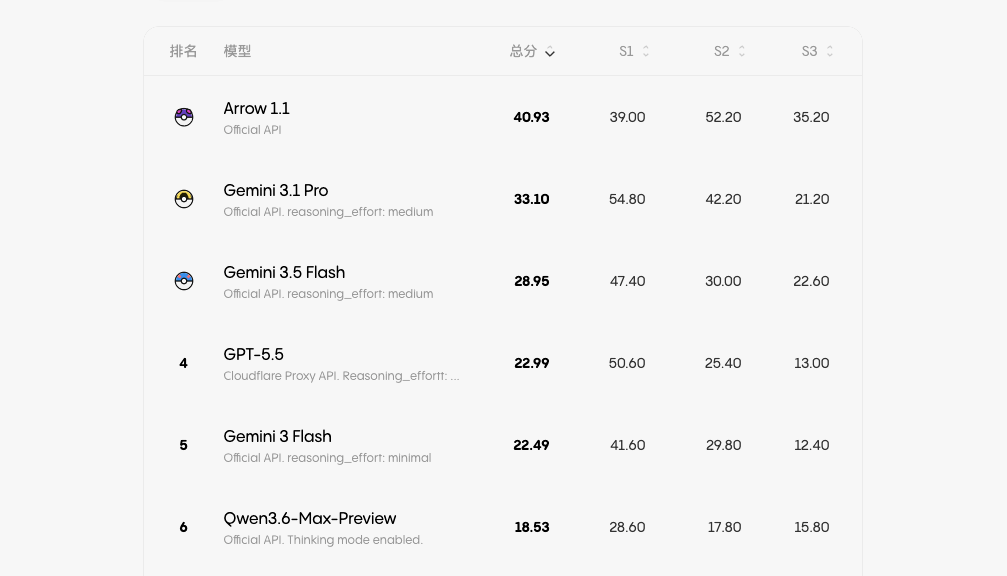
默认按照总分排序。前三名使用了大师球、高级球和超级球来作为数字名次替代。
单项评分
单项的 SVG 的评分模块是这个样子。因为是后台所以界面非常随便,基本是让模型自己随意发挥。(所以你看我前面很少放出后台截图。)
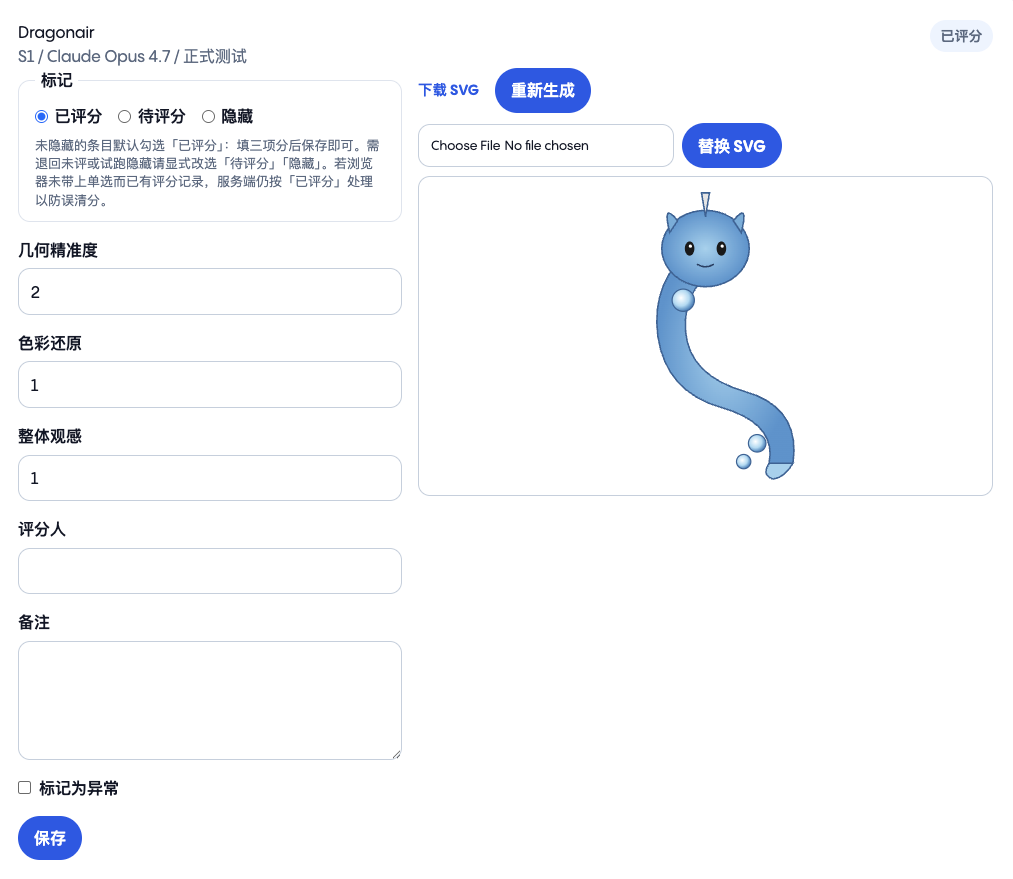
这里面需要包括:
- 正在评分的宝可梦信息:
- 宝可梦名字
- 宝可梦所在阶段
- 生成的模型
- 所在评测批次
- 标记状态,默认是已评分;
- 多维度打分
- 这里之后可能会迭代为0-10点选而不是手动填写数字;
- SVG 操作:
- 下载 SVG:有些 LLM 生成的 SVG 会因为内部注释格式错误导致不完整,需要手动去调整;
- 替换 SVG:调整后的 SVG 通过这个重新上传替换;
- 重新生成:某些队列任务虽然成功执行了,但是可能返回结果是错的,或者没有正确截断 SVG 标签,需要重新生成,并同时标记该评测结果为缺席;
- 其他
- 评分人和备注还没用过,前者是因为目前只有我自己,后者是每个都写备注太麻烦了……
- 标记为异常即隐藏状态,冗余懒得清理了😅,基本不会用到;
审核校对
由于是人工评估,所以需要校对来尽可能减少分数不公平的现象。这里主要是按照宝可梦名称,重新以分数倒序排列。
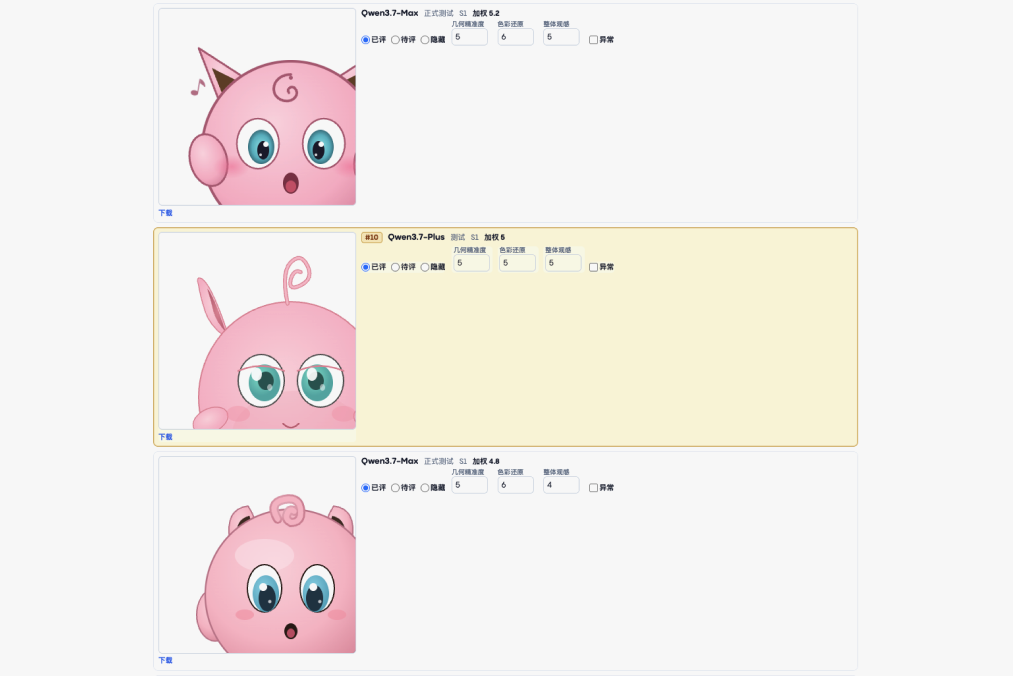
这里我会批量修改一些分数,所以只会批量保存分数。为了后续校对新模型分数,我加了黄色高亮来帮我快速识别新模型的所在位置。
到这里就可以在汇总页核实后发布,发布后才会推送到前台进入排行榜展示。也可以进行下一步后再发布。
小游戏题库管理
在关都地区的第一代动画中,Eyecatch 猜剪影小游戏就广受欢迎。正好我也有了很多宝可梦数据,做完前端排行榜第一件事就是想着把这个功能也加进来。

生成后的 SVG 会同步进入到这个题库的「草稿」状态,和「排除」状态一样不进入题库,但是需要单独区分出来去做修正。剪影逻辑也很简单,把 SVG 内所有图层填充样式改为黑色。
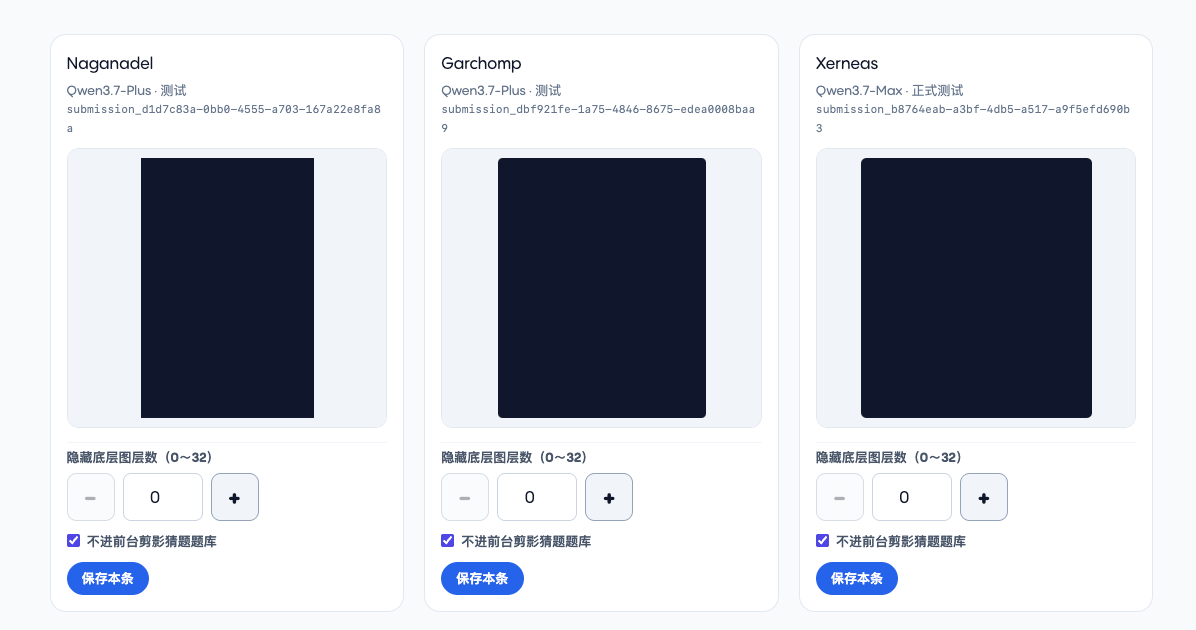
然后在后台就会发现很多 SVG 是这种情况。原因是 LLM 生成的 SVG 会带有这种大块图形。一遮挡,体形轮廓就看不到了。
前期我还在纠结如何识别出这些大面积,比如去识别接近 viewbox 尺寸的图形然后隐藏它……但实际找了几个 SVG 样本下载后发现,这些大块图形基本是背景造成的,然后我灵光一闪——这个项目的第一次 aha moment——那我直接从最底层计数,去隐藏不同数量的图层就好了!
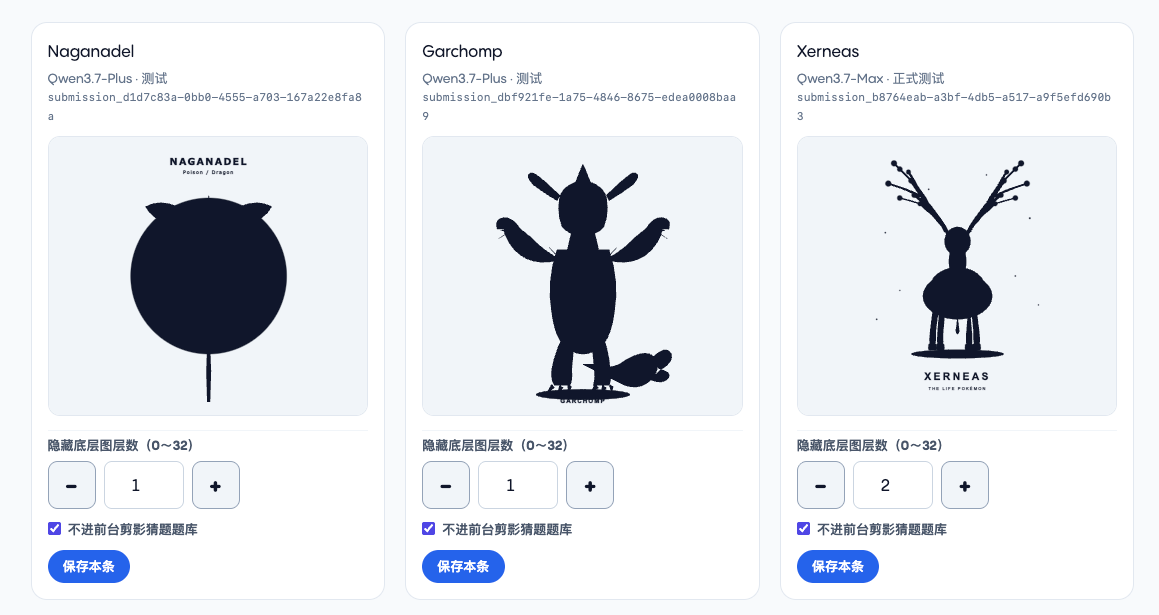
这样实现成本非常低,只需要存储隐藏层数这一数值就行。如上图所示,体形一下子就出来了。
大部分宝可梦 SVG 只需要隐藏 1-2 层背景即可展示出轮廓。像上图中还额外带有文字(大多是 Qwen 系列模型生成)就基本无法依靠这种方法消除,只能隐藏不进入题库。
前台展示是 4 选 1,10 题为一轮。理论上你遇到 10 次海星星就可以轻松满分(?)

为了还原动画效果,我还模拟了公布答案的特效,类似下图的样式。这是用 shader 实现的,你可以在 shadertoy 找到我分享的 GLSL。

发布更新
我在后台也加了 changelog 页面方便发布更新信息。
社交媒体上也需要设计新模型排行图片和总结。目前分为了两部分:
- 排行信息:包括模型本身排名、模型附近排名、同系列模型排名。
然后发现对于小红书这样的平台,只有文字信息可能没什么吸引力,于是加了个展示环节展示模型生成的雷霆作品。

以上就是后台评分流程。
前端展示
前端除了排行榜展示,还有几个点可以额外说明一下。
SVG 结构数据
我额外建立了 SVG 测试榜单,用于对比各个 LLM 生成的 SVG 结构。包括:
- SVG 体积;
- SVG 的标签数量;
- SVG 的高级标签数量占比,包括
<defs>、<use>、<clipPath>、<mask>、<linearGradient>、<radialGradient>、<filter>等; - SVG 锚点数量;
以上参数均有 S1、S2 和 S3 的单独对比。其中 SVG 锚点数量和视觉分数会按照二维坐标展示成散点图,横轴为锚点数量,纵轴为视觉分。这样四象限含义即可代表:
- 视觉分高、锚点少:简洁
- 视觉分高、锚点多:精致
- 视觉分低、锚点少:简陋
- 视觉分低、锚点多:冗杂
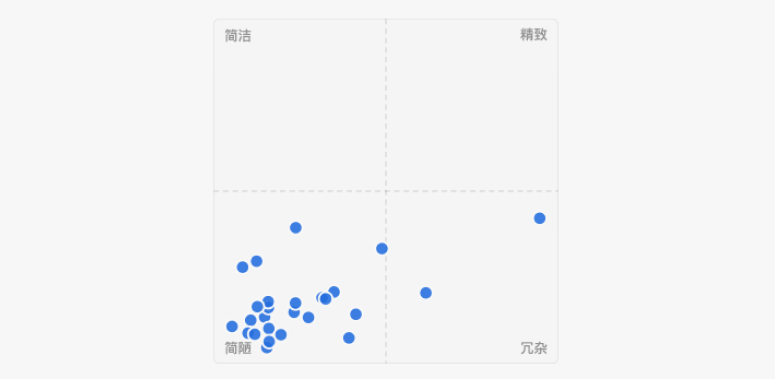
很遗憾目前只有 Arrow 和 Gemini 模型在某些维度接近「精致」,大部分情况下都是简陋。
Gallery
Gallery 页面用于展示按照宝可梦和按照模型来查看所有生成的 SVG 数据和分数情况。
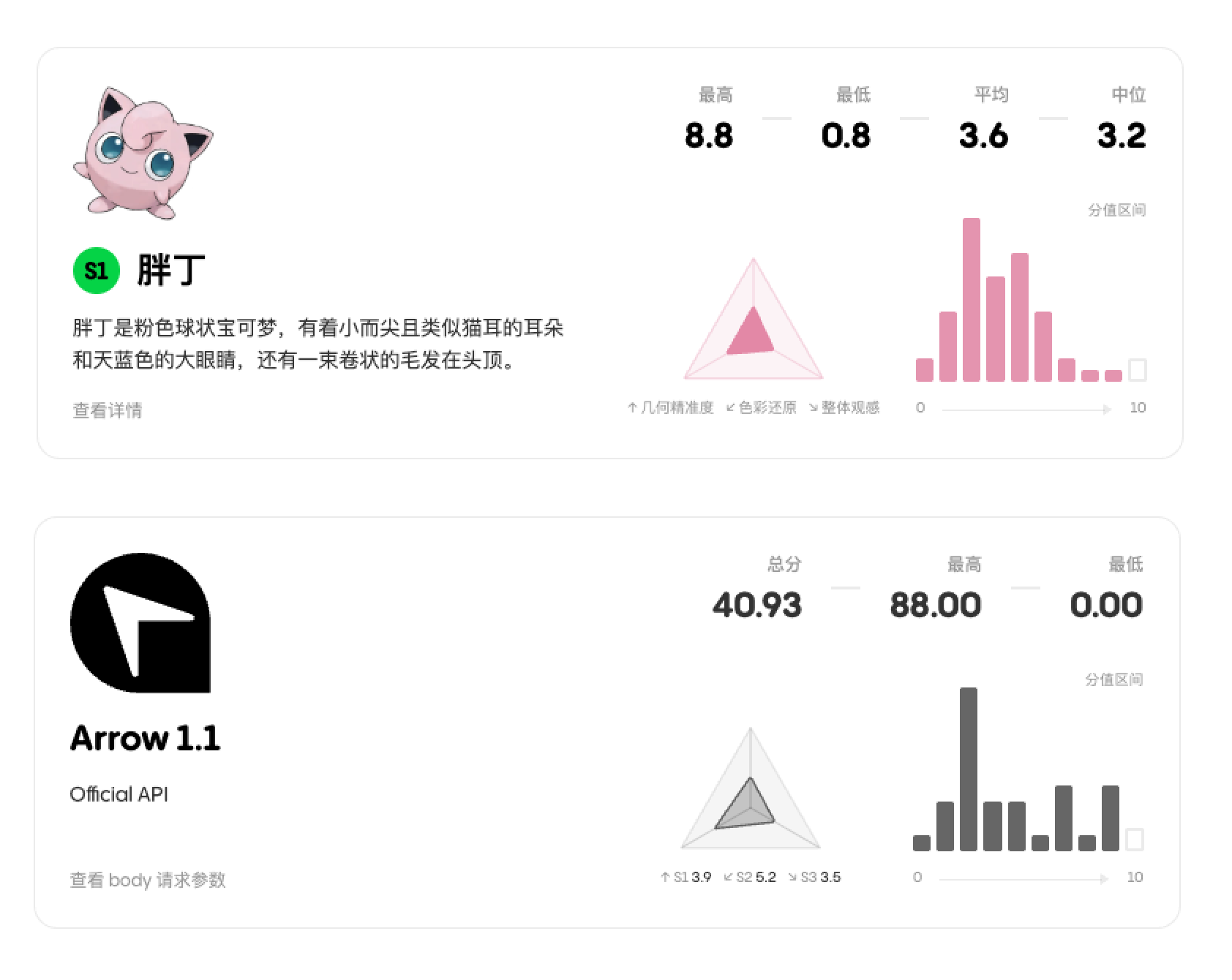
按宝可梦查看时,可以看到这个宝可梦下分数的最高分、最低分、平均分和中位数。从 0-10 划分了 10 个区间,显示分数都落在了什么范围。以及三角雷达图展示三个维度的均分。
按模型查看时同理,新增了查看 body 请求参数,读取的是后台同款字段,以保证公开透明。
展望
至此基本就是 Pokémon SVG Bench 的全部内容。目前 bench 还缺少像是 webhook 通知和总体流程的可观测性,草台的骨架已经搭建起来了,但是还没法细看。
这也是我第一个让 LLM 「一句话」跑长任务的项目,之前都是我自己主动去拆分项目的迭代,这次跑出来的后台基本很粗糙,有些地方甚至不知道怎么用,导致后续很长时间都在迭代交互体验。两种方式各有优劣。
以上是我在这项目中学到的内容。
注 1:封面的烈咬陆鲨由 Gemini 3 Flash 生成,像是 Android 机器人的远方表亲,有一种迷之可爱。更多你可以在这里查看。
注 2:另外我在看一些远程工作优先的全职或非全职界面设计工作机会。有意向请邮箱联系。
如果你觉得文章对你有些帮助,可以请我的猫吃罐头 ↓
