#89 Tana 迷雾
我对 Tana 的不满之处

大家好,我是使用 Tana 时长两年的个人练习生 fenx,喜欢读、写、bullet 和标签。MUSIC!
▶️ 安静 (周杰伦) —○——— 1:20 / 5:34
上周 Tana 正式结束邀请测试,登陆 Product Hunt 并取得了不错的反响(week#1)。无论你用 Deep research 还是查看讨论,都能感知到它是一款优秀的 PKM 产品。就像它的前辈 Logseq、Workflowy 一样,基于节点,并用 supertags 连接和配置一切。全面的查询语句,继承自 Notion 的对象属性,邃密的指令功能让 Tana 远超出 outline 应用功能。
在 Tana 的官网导航列出了很多应用场景,非常推荐查看一下。

社区内也有不少入门视频,带你领略 Tana 的魅力。我也手动提取了官方的帮助文档,你可以将这个 txt 文件直接嵌入模型当做知识库。
但是,本文并非介绍如何 Tana。而是帮助你考察一个新 PKM 工具时,给予一些建议——特别是难以察觉的「逆耳之言」。
文档支持
Tana 的格式和 markdown 很像,但非常遗憾是它不支持直接解析 md 格式。也就是说,你复制粘贴进去的 ** 、~~、- 等符号都会作为纯文本保留,仅换行会分节点。
这大概会给很多人致命一击,2025 年还有不支持解析 md 格式的应用?你好有的。
在 Tana Paste 文档中,可以看到你应该以这样的格式直接粘贴进 Tana 才会被解析:
%%tana%%
!! 标题
- **加粗文本** ^^高亮文本^^ #[[supertag]]
- 子节点文本 __斜体文本__
- 子文本
- field 1:: field 值
- field 2:: [[多个 field 值]]
- %%search%% 搜索节点
* OR::
* 条件 1
* 条件 2
* 筛选的 field:: 条件 3
- [[节点名称^节点 ID]]
- [[date:2025-02-28]]
- [插入链接](https://tana.inc)
- 
其中 field 本应有多种类型,但是在 Paste 格式中没有区分。
该格式本身不是为大量处理数据而生,所以 Tana 在长文章支持上很弱,只有基础的富文本编辑。而且其他 App 的数据导入也成问题,官方只支持 Roam、Logseq 和 Workflowy/OPML 导入,其他格式只能自己编写转换脚本。在 Tana Paste example scripts 这个 repo 里可以看到一些 mjs 脚本。
或者是官方更推荐的使用 AI 让其结构化输出,这也是后面我会提到的诟病之一。
离线模式
目前没有 → 官方 QA
从迭代趋势来看,离线本地运行一直不是 Tana 团队的重点。如果你很看重这点的话,那么 Tana 很长一段时间都不会适合你。
另外 Tana 依赖大量 Google 服务,如果你的企业防火墙阻挡了 Gmail 那么大概率也无法正常使用 Tana。
导出支持
Tana 支持导出整个 workspace(内容最大单位)的 json,但是导出的 json 包含了大量 nodeID 等冗余信息,像这样的:
{
"currentWorkspaceId": "XXXXXXXXXXX",
"docs": [
{
"id": "SYS_T01",
"props": {
"_docType": "tagDef",
"_metaNodeId": "SYS_T01_META",
"_ownerId": "SYS_T00",
"created": 1739343247171,
"description": "The Core supertag. The supertag for the supertag nodes",
"name": "supertag"
}
},
{
"id": "SYS_C01",
"props": {
"_metaNodeId": "SYS_C01_META",
"_ownerId": "SYS_T41",
"created": 1739343247171,
"description": "Describe what this app is for",
"name": "Description"
}
},
...
可读性极差,清洗价值低,前几百行都找不出个有用信息。
后来 Tana 更新了 Copy as Tana Paste 和 Copy as plain markdown,情况有所缓解,但功能上来说依然很潦草。
AI, API 与 会员
Tana 中可以直接发起 API 请求做为指令,并可以将指令打包起来插入到几乎任何地方。这个功能非常强大,也是我觉得其他 PKM 产品没有做到的地方。举个例子,你可以新建个每日新闻模板,配置好仅需一键便可通过 API 获取今日新闻和天气信息。低代码万岁。
但是——
Tana 的主推策略是什么都得和 AI 强绑一下。比如你可以建立 3 个 prompts,将其做为某个指令的 3 个选项,这看起来很不错。但是到 API 解析这里你也只能寄希望于 AI 为你结构化输出,否则返回 json 只能作为一坨纯文本输入。
更别说 POST 模式时 payload 内容(也就是 body 请求内容)格式也有去换行需求和种种限制,你只能通过 ${Field Name} 调用父节点下的 field 值;要是直接引用某个节点的话,[[]] 会被直接格式化为文本,从而和 json 中的 array 格式冲突……
而 AI 正是 Tana 会员的收费点。
会员
无论是 8 美元每月的 Pro 还是 12 美元每月的 Core 会员,AI 功能都是其中的重点。免费用户即使有自己的 API key 也无法使用。你没有更多的模型选择,只有 OpenAI 和 Claude(微调的重心也是前者)。自定义模型和自定义 API Key 都是不存在的。
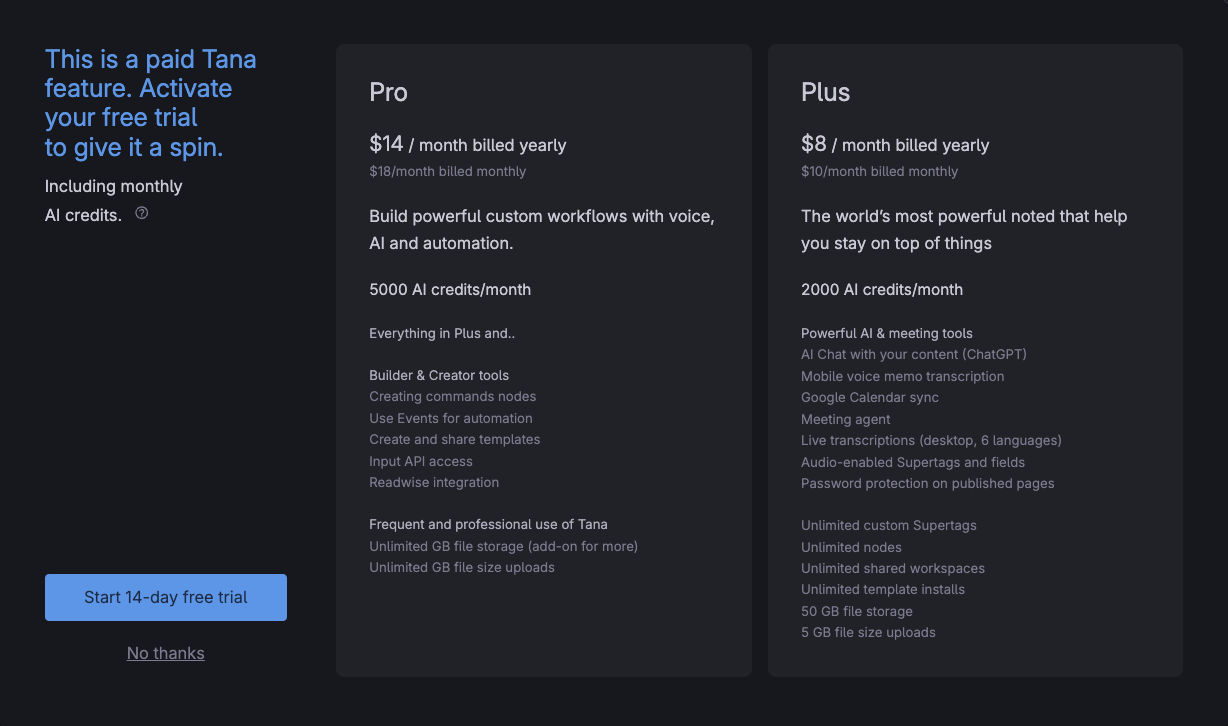
这种只差临门一脚的「卡脖子」行为,正是我感到很不舒服的地方。使用 Tana 到这里的人会看不出来你的小心思吗?该开放的地方开放,去贩售核心买点而不是对完整功能上锁,才是理想中会员模式。朋友说有这有点像米哈游的命座 / 星魂 / 影画,有时就得多抽几命才能体验完整,你看 Tana 还便宜着呢。我嘴上说 Tana 罪不至此,但心里也是默默赞同。
说回正题,上面的会员服务对我来说价值不太高。Google 日历和语音记录那些目前完全用不到,其他功能多少也是可有可无,这让我进退两难。Tana 为了解决这种焦虑,直接在免费套餐里定义了 20,000 个节点上限。如 Reddit 上评论所说,「这种模式让我感觉,我在使用一个早晚会抛弃的服务。」我理解小团队的艰难,所以我依然会观察 Tana 一段时间。
话说能在哪里看到,已经使用了多少节点呢?貌似也没有。
发布到网络
API 方面,Tana 支持 Input API,且仅支持 POST,想要 GET 的话还得再等等。也就是说目前仅支持其他应用向 Tana 写入数据,在 Tana 写的很多东西却无法分享。这点上远不如 Notion 和 Capacities。
很急。
某月某日,Tana 发布了 Publish 功能,这是我非常期待的功能,也是一个让我感到无比失望的功能。
它的功能是发布某个节点到网络上,其他人可以公开查看。但是界面无比简陋,以至于毫无分享欲望。
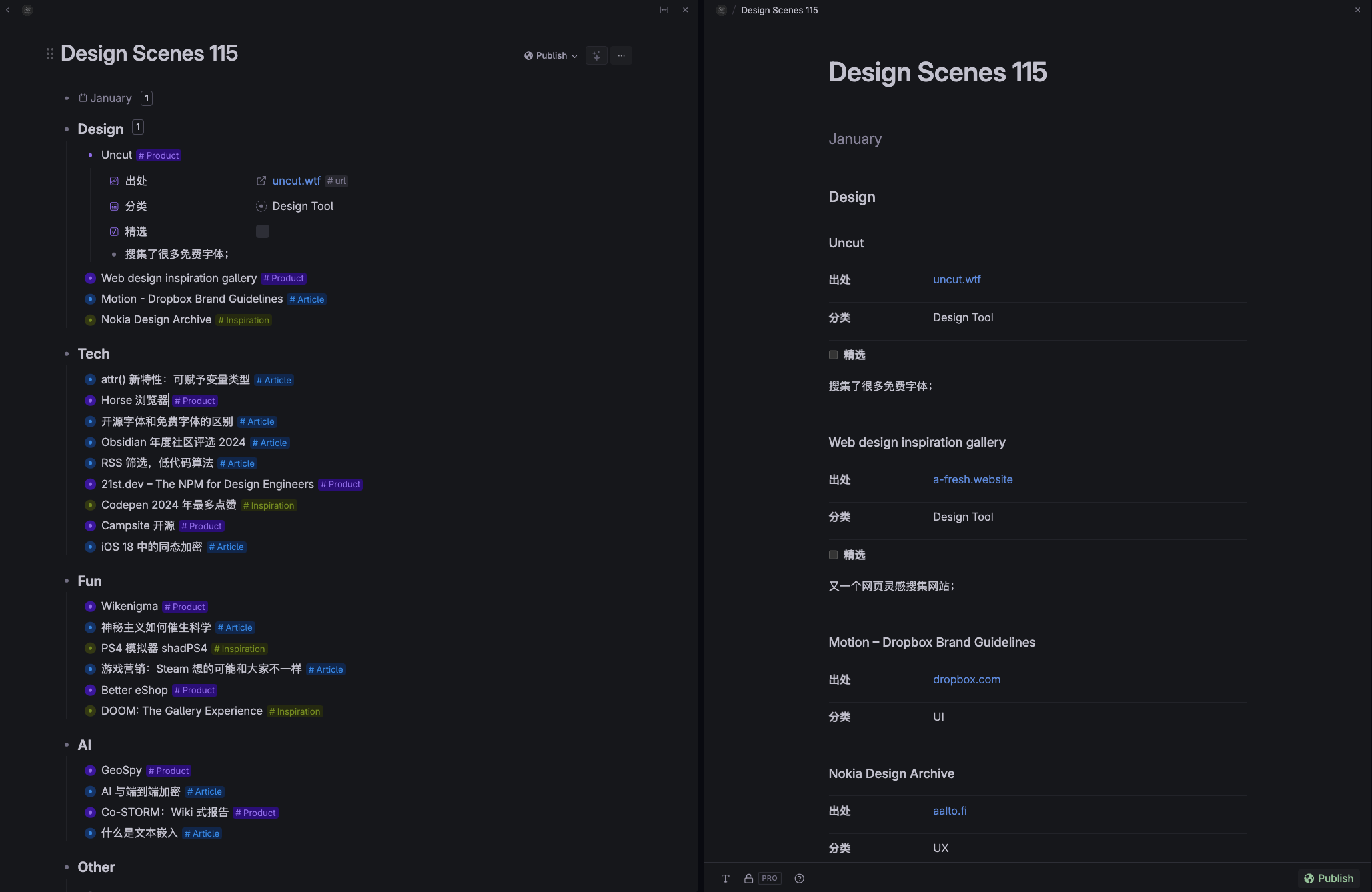
如上图右侧样式,这已经是我尽力调整过的了。不支持自定义 CSS 就算了,能像左侧编辑模式一样也可以啊,结果这个样式……他真的我哭死(贬义)。
之后打算设计一个工作流来独立展示 Tana 上的这些内容。
半成品表达式
文本表达中,逻辑的构建是富文本之上,通往知识库的康庄大道。
Tana 支持一些简单的表达式从 field 取值。比如下方节点结构中:
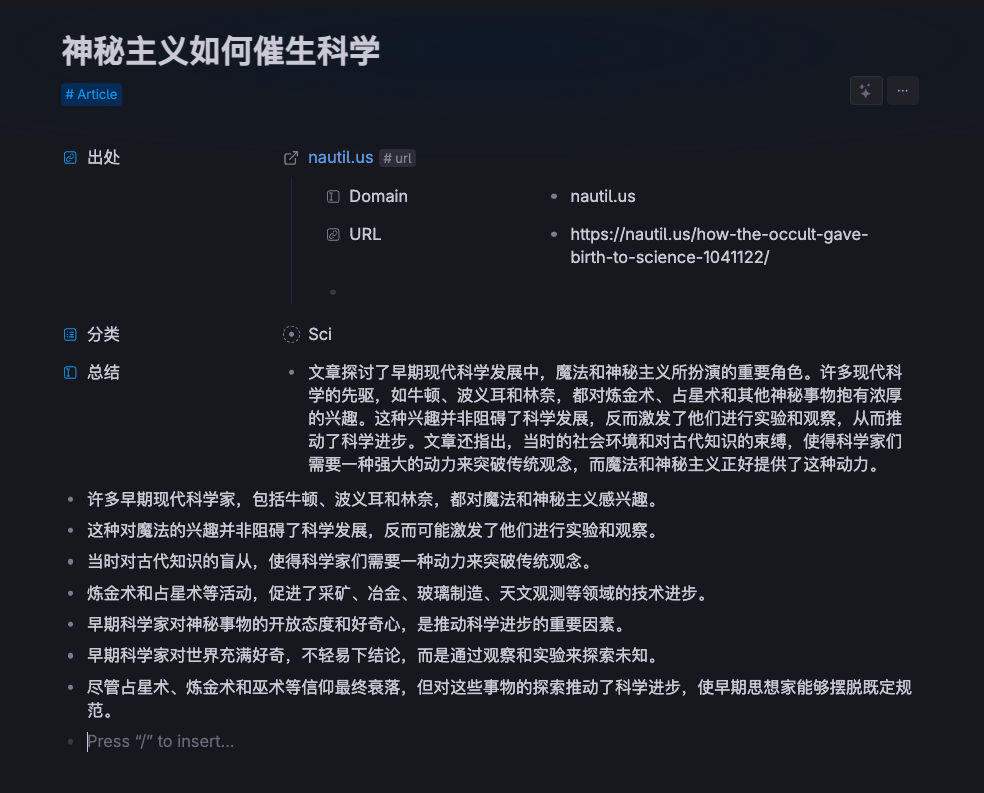
在 #Article 下,${name} 代表标题自己输入, ${总结} 即可调用总结属性对应的信息,${总结|30…} 代表取总结信息的前 30 字符。还有一些系统默认属性(比如节点创建时间)可供调用。
除此之外,没了。
这让我很费解,Tana 支持表达式,但是却只用在节点筛选(Node Filter 属性)上,而无法精确取值。比如上图中我为 #url 所赋予的 Domain 属性,明明可以从 URL 中通过正则获取,但我需要手动输入。近几个月我在高强度使用快捷指令(Shortcuts),了解到完整的逻辑建立在任何系统都非常有用。希望 Tana 不要止步于此。
其他体验
Tana 的界面说不上精致,但是能用下去。唯独 ⌘ + K 这个上下文菜单让我感到了交互困惑。
它是这样的:
- 在不同的地方按下
⌘ + K会有不同的上下文菜单,界面上没有区分; - 这个菜单很长,顶部加了搜索也只是权宜之计。没有分组优化,进一步加大了新用户上手难度;
- 无法定制。制作的指令不会在这里列出,这个是产品逻辑限制;
另外 Tana 帮助文档给我的感觉是,它是为能看懂文档的人而写的——不懂的人看了文档也是不懂,它缺少很多细节例证和默认值。比如可以看看这篇 AI 指令文档。
总的来说
允许我再次重申一下,本文并非阻止你使用 Tana。我很乐意向大家推荐去使用它,一旦解锁了 AI,Tana 能做很多事情。我自己也在上面记录了很多,并 copy 全文 as markdown 放到了知识库里。但也不得不说明出短板来节省你的时间。你可以在官方反馈列表中看到更多尚未满足的需求。据我的感知 (?),核心用户更集中在他们的 slack 群,所以基本会优先满足他们的需求。
Tana 的 Roadmap 停留在去年的 8 月份,2025 年的还没有更新。不过能看到的是,Tana 完成了由 Tola Capital 领投的 1400 万美元 A 轮融资,总融资额达到 2500 万美元。财务状况比较乐观,希望 Tana 多招聘点能人多完善产品吧!
如果你觉得文章对你有些帮助,可以请我的猫吃罐头 ↓
